

Doc2Graph: Turn Documents into Specific Knowledge
Upload or select documents
In your dedicated repository, provide and select documents to initiate the transformation.
Step 1 – Document to Text
Doc2Text converts any document into clean text and a hierarchy based on titles and sections.
Step 2 – Chunks
We split content into coherent chunks and vectorize them.
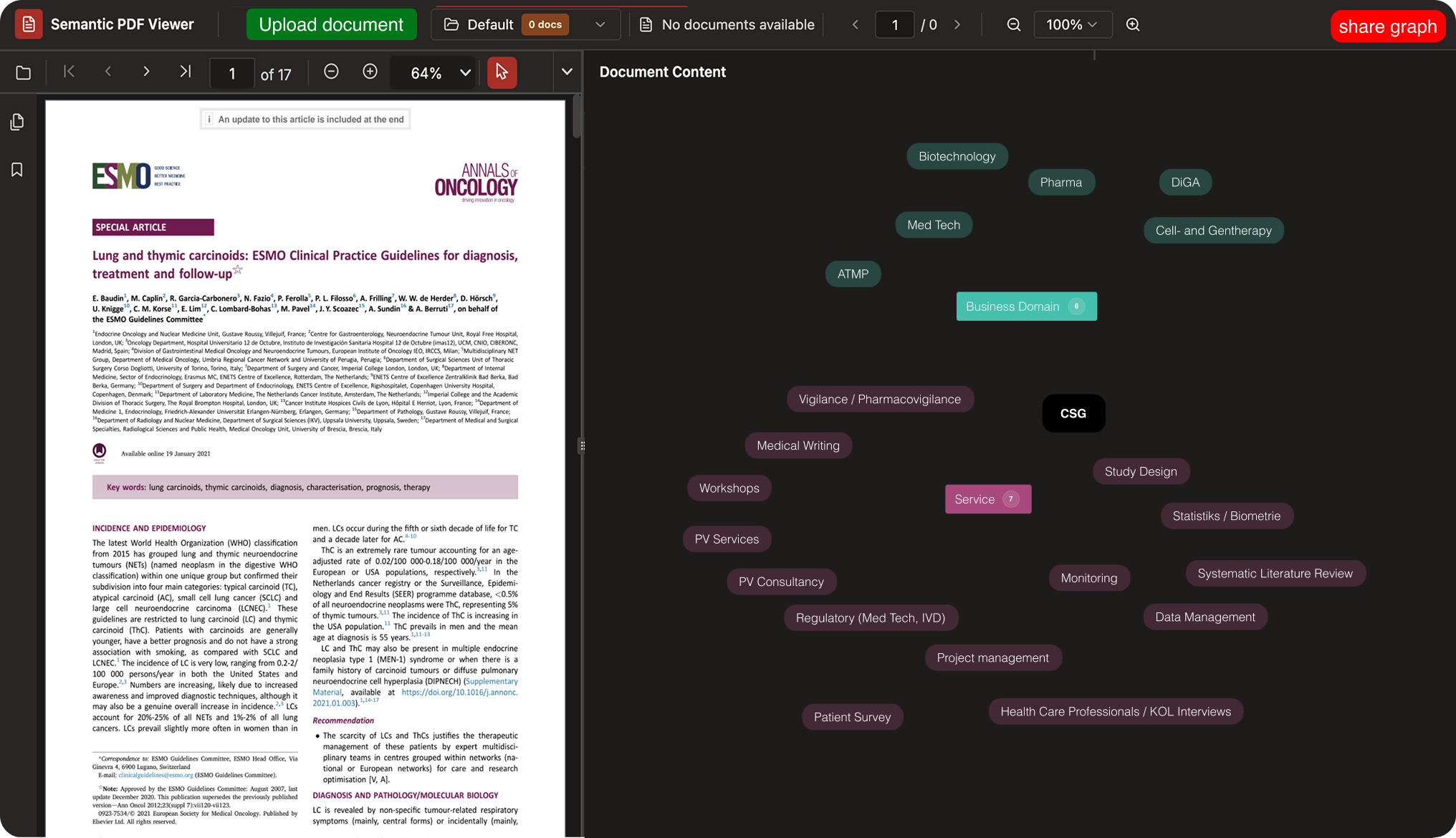
Step 3 – Explore
Explore documents as a connected knowledge graph.
Tools Exist, but Applying Them to Create Value in a Regulated Environment Requires Precision
In regulated environments, generic AI solutions need to be adapted to meet specific business requirements. Each Life Sciences organisation operates within a unique context, shaped by EMA, FDA, or ICH regulatory constraints. Applying a one-size-fits-all approach to every use case is inefficient and often counterproductive when developing effective AI solutions.
Out-of-the-Box Means Generic, Built for No Specific Requirements
Out-of-the-box AI pipeline tools process document corpora using technically sophisticated methods, but lack business-specific context. As a result, they often produce undifferentiated outputs that blend domain knowledge, blur distinct business terminologies, and overlook the nuances of your organisational context.
Low signal-to-noise knowledge extraction from heterogeneous document types
Generic or misaligned reference terminologies and ontologies
Little awareness of your specific constraints and/or value assessments
Poor audit traceability incompatible with GxP environments
Value Comes from a Precision-Engineered Pipeline Tailored to Your Needs & Constraints
We bring the technology and the expertise to map it exactly to your organisation’s structure, vocabulary, and compliance obligations. The graph becomes a living representation of your knowledge, not a generic approximation of it.
High signal-to-noise knowledge extraction based on specific requirements
Fit-for-purpose reference data corresponding to your use cases and context
Calibrated and transparent AI solutions based on your risk tolerance
Full traceability layer for inspection-ready audit trails
Aligned with the data standards of your choice
Many organisations have access to the same AI tools, but fewer know how to adapt them to their data, context, and constraints
The Doc2Graph Pipeline is Built on Three Core Transformations
Doc2Txt
Document ➞ raw text
Transform any document into text without formatting.
Txt2Chunk
Text ➞ Vectors
Transform text into machine-readable arrays of numbers.
Txt2Graph
Text ➞ nodes and relationships
Extracted concepts become nodes, while the actions between them become relationships in the graph
See Doc2Graph in Action

Your First Step Towards Becoming an AI-Driven Organisation
Phase 1 – Define clear requirements and what success looks like: Guided by clear, digitally captured requirements, our AI-enabled pipeline extracts only the fit-for-purpose entities from your document corpus.
Phase 2 – Increase signal-to-noise ratio: An IT system is only as smart as the data available to it. Based on your requirements, our pipeline extracts only the concepts and relationships relevant to your use case. We then validate them through a combination of machine-driven and human-in-the-loop quality checks based on rules that apply.
Phase 3 – Enrich AI input with context: Beyond document content, we enrich extracted knowledge with critical contextual information such as document metadata, business processes, external standards, and project management data, creating a complete, AI-ready view.
Place Evidence at the Heart of Decision-Making Across Your Organisation
Documents alone are an outdated way to convey knowledge. Transforming them into structured, flexible, and enriched graph data is the first step towards a truly data-centric digital transformation
